I consume textual media from various sources: RSS feeds, Reddit, friends sharing links, etc. In conversations, I would often find myself saying “I read that somewhere, I can’t remember where”, and then try to turn to Google to find the article again, never to find it.
I also struggled to internalize the ideas, concepts, and conclusions from the media I consumed.
To try to fix this, I added some structure into how I read and process articles, blog posts, papers, and even podcasts, so that I could make better sense of them, and hopefully gain some deeper understanding of the subjects I was reading about.
After months of experimentation, I developed a process that works for me. It revolves around using Zotero and Obsidian together. By using standardized, day-based, nested collections in Zotero and an idempotent import template in the Zotero for Obsidian plugin, I can easily refer to past articles, and refer to them when writing long-form notes or articles in Obsidian.
Goals
This process aims to:
- record and organize papers, articles, blog posts, podcasts, and other media, with some metadata (when I read them, notes about them, etc), ideally with minimal effort;
- if possible, include a way to store snapshots of the media;
- integrate with my existing Obsidian vault.
Obsidian is a very popular Markdown editor, and I have been using it daily as a way to write down pretty much anything: journal entries, daily todoes, longer form notes about subjects I’m starting to learn, how to properly file my taxes… It has a rich plugin ecosystem that can change it from an editor to a full dashboard for your life.
Zotero
Zotero is the de facto tool for collecting and annotating academic articles. It can automatically add items based on ISBN, arXiv ID, DOI, and other well-known identifiers. The Zotero browser extension, called the Zotero Connector, also acts as a power web clipper so you can ingest blog posts and articles from the web. With version 7.0, Zotero introduced the ability to highlight and annotate locally saved web snapshots—an essential feature in my workflow.”
To organize my daily reading, I created a top-level collection called Daily, which is then organized in subcollections. See the tree
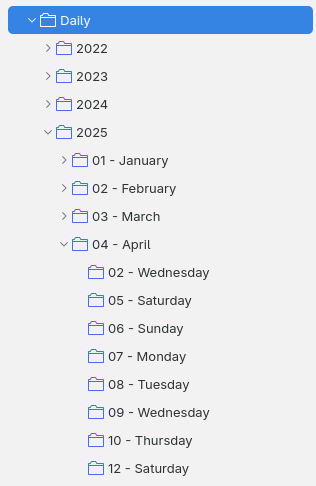
Figure 1: Screenshot of my Daily Zotero collections.
This structure acts both as a way to remove the friction of deciding which collection an article should go into, and to provide some structured metadata to help integration with my Obsidian vault. I always start by adding an article into its appropriate daily collection and, once I’ve read and understood the article a bit more, into a more topical collection, e.g. “Compiler Development”. As for the latter, collections are included in an easily parsable field using Dataview, making programmatic imports and querying into Obsidian easy.
Another Zotero option that I like to enable for this use case is the
extensions.zotero.recursiveCollectionsoption. As the name implies, it means that parent collections also show the items in their children collections. This makes it easier to do literature retrospectives, as I can easily look at a month’s worth of reading by choosing a month’s collection. The setting is only available through the Config Editor at Edit→Settings→Advanced→Config Editor. It’s a similar interface to Firefox’sabout:config.
I considered and tried other options for tracking articles, like adding a read-on-date key in the Extra field in Zotero, or as a tag, but I always ended up either forgetting, or simply dropping an #inbox tag and then never looking at the article again. Moving the data collection at ingestion time made me do it more consistently. Let me know if you have a better solution!
Obsidian
On its own, Zotero offers a functional setup. You can easily access and search through a day or a month’s worth of articles, and the literature notes associated with them. Still, I wanted to explore the possibility of integrating this data into Obsidian, as it is where I draft most of my long-form notes and articles, and the idea of having all of my notes searchable from one location was pretty appealing.
The main enabler for this is the Obsidian-Zotero integration plugin for Obsidian. It allows you to import citations, notes, and even PDF annotations from Zotero into Obsidian. My workflow here is a modified version of Alexandra Phelan’s, described here and here.
The Zotero integration plugin allows you to import items from your Zotero collections following a user-defined template. The Zotero item is imported as Markdown file with arbitrary metadata. The templating system is based on Mozilla’s Nunjucks system. It is a decent templating system, but so far it does feel as powerful as Jinja.
One of the goals of importing my notes from Zotero was idempotency and bulk imports. I wanted to be able to modify items in Zotero, and have the changes reflected back in Obsidian. (This is a one-way street, I do not and cannot modify Zotero items from Obsidian). To do so, I use the Zotero unique item id (shown as key in the image below) as the imported file name.
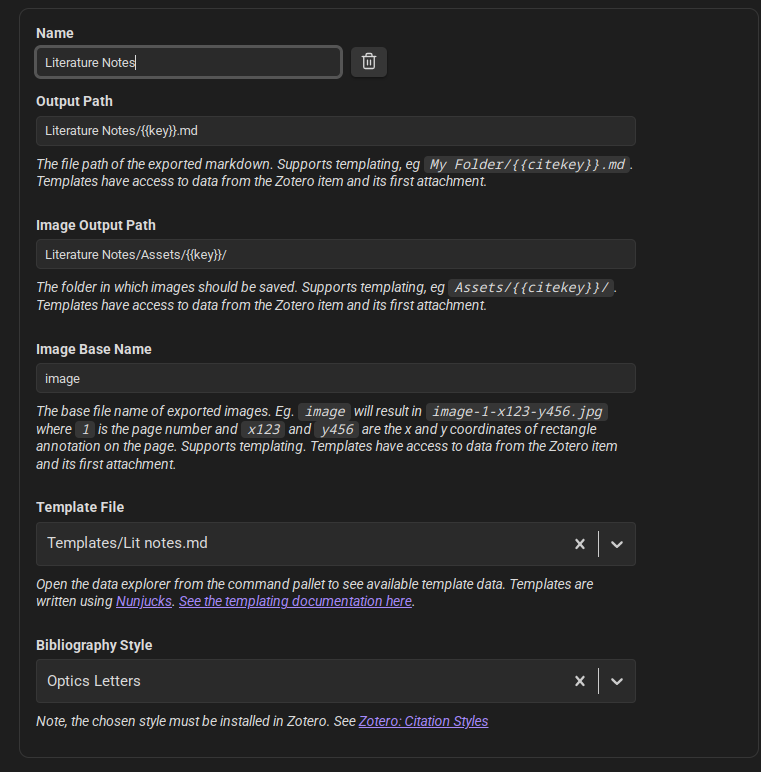 Figure 2: Settings used to allow for idempotency for bulk imports and re-imports from Zotero to Obsidian.
Figure 2: Settings used to allow for idempotency for bulk imports and re-imports from Zotero to Obsidian.
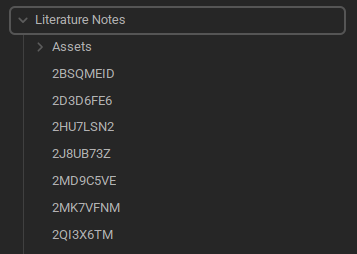
Figure 3: File listing of literature notes imported from Zotero in my Obsidian vault.
This seems like it would limit search, but you can fix it by adding aliases in the import, e.g. the title of the item. That is a good segue to talk about the Nunjucks template that I use.
The Nunjucks templating system is very flexible. It allows for looping constructs and some conditional logic. My own import template is pretty long, with approximately 90 lines, so I’ll break it down here. You can see the full template here.
Let’s start by looking at the YAML frontmatter. There’s a lot in there, but for me the most important fields are title, year, aliases, and collections. Both the title and aliases are indexed by Obsidian search (and Omnisearch), so when you want to link to a Zotero import, starting to type [[]] will give you suggestions based on the title or citekey, so you can easily search by author or title. I use the collections field for a specific DataviewJS query that allows me to see what articles I’ve read on a particular day in my daily note, but this is a topic for another day.
---
title: '{{title | replace("'", "\"")}}'
year: {{date | format("YYYY")}}
citekey: "@{{citekey}}"
{% if itemType -%}
itemType: {{itemType}}
{% endif -%}
{% if itemType == "journalArticle" -%}
journal: {{publicationTitle}}
{% endif -%}
{% if itemType == "podcast" -%}
podcastSeries: "{{seriesTitle | lower}}"
{% endif -%}
{% if volume -%}
volume: {{volume}}
{% endif -%}
{% if issue -%}
issue: {{issue}}
{% endif -%}
{% if itemType == "bookSection" -%}
book: {{bookTitle}}
{% endif -%}
{% if publisher -%}
publisher: {{publisher}}
{% endif -%}
{% if place -%}
location: {{place}}
{% endif -%}
{% if pages -%}
pages**: {{pages}}
{% endif -%}
{% if DOI -%}
doi: {{DOI}}
{% endif -%}
{% if ISBN -%}
isbn: {{ISBN}}
{% endif -%}
aliases:
- "{{citekey}}"
- '{{title | replace("'", "\"")}}'
dates_edited: []
{% if collections -%}
collection:
{% for collection in collections | filterby("fullPath", "startswith", "Daily") -%}
- {{collection.fullPath}}
{% endfor -%}
{% endif -%}
---
As for the note content itself, there are a few things that I wanted to be able to do:
- search through the abstract of the item;
- search through my notes;
- see which collections an item belonged to;
- import Zotero tags into Obsidian tags;
- navigate to the item in Zotero from Obsidian;
- use the graph view to see related articles;
Let’s go through the content block by block. There are a lot of brackets, and escaping of quotes, so brace yourself (pun intended).
## [{{title}}]({{desktopURI}})
{% if hashTags -%}
{{hashTags | replace(",", " ")}}
{% endif %}
### Attachments
{% if attachments %}
{% for attachment in attachments | filterby("path", "endswith", ".pdf") -%}
- [{{attachment.title}}]({{attachment.desktopURI}})
{% endfor -%}
{%- endif %}
The first heading is a link that will open up Zotero at the particular item. This will render to something like this:
[Never Split the Difference: Negotiating As If Your Life Depended on It](zotero://select/library/items/2QI3X6TM)
a type of link you’re used to seeing if you use the Zutilo plugin.
The two next blocks import the tags, and ensure that they are formatted in a way that Obsidian understands (not comma separated, but space separated).
## Reference
{{-bibliography.slice(2,-1)}}
## Collections
{%- for collection in collections %}
- [{{collection.fullPath}}](zotero://select/library/collections/{{collection.key}})
{%- endfor %}
The Reference block only shows the rendered citation based on your citation style. Honestly I don’t use it that much, but it’s a nice to have. The other block shows which collections the item is a part of, and allows you to navigate to the collection in Zotero by clicking the link.
## Notes
{% for note in notes -%}
### [Note {{loop.index}}]({{note.desktopURI}})
{{note.note}}
{%- endfor %}
## Abstract
{{abstractNote}}
## Related notes
{% for relation in relations -%}
- [{{relation.title}}]({{relation.itemKey}})
{%- endfor %}
I then import all of my notes as-is in Obsidian, and provide a Zotero link to the note itself. The abstract is a simple block of text to import. I also import the related items in Obsidian, and that builds up the local graph view in Obsidian, increasing discoverability of notes.
Conclusion
Overall, I am satisfied with this workflow, even though there is more overhead than I would like to. Adding blog posts and web pages to Zotero can take a bit of time, as not all sites publish proper metadata, and I need to manually tweak the items. For some types of media, like podcasts, writing a Zotero translator (like this one for LWN) would probably save me some time.
Appendix: Essential Tools and Plugins
- Zotero;
- Better BibTeX plugin (to populate the `` field);
- Zotero browser extension;
extensions.zotero.recursiveCollectionsto see nested collections’ items in the parent collections;
- Obsidian;
- Zotero Integration plugin;
- Dataview (optional, but very convenient to query literature notes).